



Deepseek, until recently, a little -known Chinese artificial intelligence company, the technology industry conversation has been made after it implemented a series of large language models that eclipse many of the world’s leading developed developers.
Depseek launched its most expelled large language model, R1, on January 20. The IA assistant arrived at No. 1 at the Apple App Store in recent days, increasing the long dominant openai chatgpt to number 2.
His sudden domain, and his ability to overcome the US models in a variety of reference points, Silicon Valley have sent to a frenzy, especially when the Chinese company promotes that its model developed to a cost fraction.
The shock within the technological circles of the United States. On the other hand, researchers are realizing, these efficient processes may be in terms of cost and energy consumption, without compromising capacity.
R1 arrived immediately after its previous model V3, which was launched at the end of December. But on Monday, Depseek launched another high performance AI model, Janus-Pro-7b, which is multimodal in the sense that it can process several types of media.
Here are some characteristics that make Deepseek’s large language models look so unique.
Size
Despite being developed by a smaller team with funds drastically less than the main American technological giants, Depseek is hitting over its weight with a large and powerful model that works so well in less resources.
This is because the AI assistant is based on a “mixture of experts” to divide its great model into numerous small submodels or “experts”, with each specialized in the management of a specific type of task or data. Unlike the traditional approach, which uses each part of the model for each entry, each submodel is activated only when its particular knowledge is relevant.
So, despite the fact that V3 has a total of 671 billion parameters, or configurations within the AI model that adjusts as it learns, it actually only uses 37 billion at the same time, according to a technical report published by its developers .
The company also developed a unique load strategy to ensure that no expert is being overloaded or subjected with work, using more dynamic adjustments instead of a traditional penalty -based approach that can lead to worsened performance.
All this allows Deepseek to use a robust “expert” team and continue adding more, without slowing down the entire model.
It also uses a technique called inference computer scale, which allows the model to adjust its computational effort up or down depending on the task in question, instead of always executing at full power. A direct question, for example, could only require a few metaphorical gears to turn, while asking for a more complex analysis could make use of the complete model.
Together, these techniques make it easier to use such a large model in a much more efficient way than before.
Training cost
Deepseek’s design also makes its models cheaper and faster to train than those of its competitors.
Even when the main technological companies in the United States continue to spend billions of dollars a year in AI, Deepseek states that V3, which served as the basis for the development of R1, took less than $ 6 million and only two months to build. And due to US export restrictions, which limited access to the best computer chips, namely, the NVIDIA H100, Deepseek was forced to build their models with the least powerful NVIDIA H800.
One of the company’s greatest advances is the development of a “mixed precision” frame, which uses a combination of 32 -bit 32 -bit floating numbers (FP32) and 8 -bit numbers of low precision (FP8). The latter uses less memory and is faster to process, but it can also be less accurate.
Instead of trusting only one or the other, Deepseek saves memory, time and money through the use of FP8 for most calculations, and changing to FP32 for some key operations in which the accuracy is essential.
Some in the field have indicated that limited resources are perhaps what forced Deepseek to innovate, racing a path that potentially demonstrates that AI developers could be doing more with less.
Performance
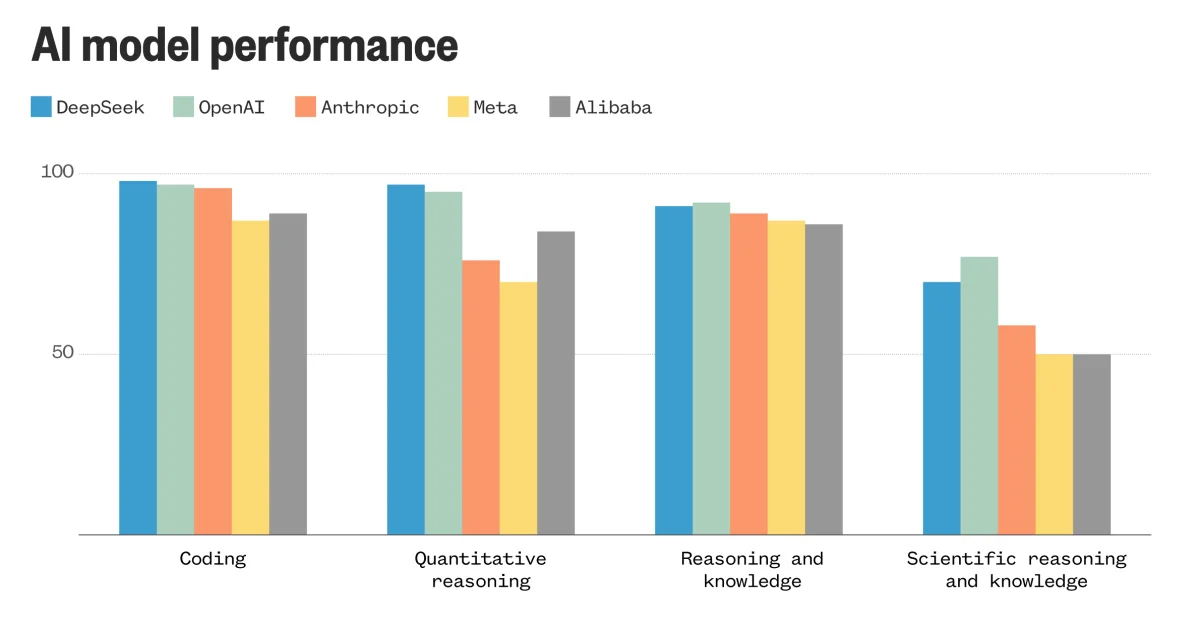
Despite its relatively modest media, Depseek scores in reference points maintain the pace of the latest avant -garde models of the main developers of AI in the United States.
R1 is almost the neck and neck with the OPENAI O1 model in the artificial analysis quality index, a classification of independent AI analysis. R1 is already overcoming a variety of other models, including Gemini 2.0 Flash from Google, the sonnet Claude 3.5 of Anthrope, the flame goal 3.3-70b and the GPT-4o of OpenAi.
One of its main characteristics is its ability to explain your thinking through the reasoning of the chain of thought, which is intended to divide complex tasks into smaller steps. This method allows the model to retrace and review the previous steps, imitating human thought, while allowing users to follow their reason.
V3 was also acting on par with Claude 3.5 Sonnet after its launch last month. The model, which preceded R1, had surpassed GPT-4O, calls 3.3-70b and qwen2.5-72b of Alibaba, the model of the previous leader of China.
Meanwhile, Depseek states that his new Janus-Pro-7B surpassed Dall-E and the stable diffusion of OpenAI and the stable dissemination medium in multiple reference points.



